
Tuesday, December 17, 2013
Monday, December 16, 2013
Mobile Robotics: Mathematics, Models, and Methods
New book

Mobile Robotics offers comprehensive coverage of the essentials of the field suitable for both students and practitioners. Adapted from Alonzo Kelly's graduate and undergraduate courses, the content of the book reflects current approaches to developing effective mobile robots. Professor Kelly adapts principles and techniques from the fields of mathematics, physics, and numerical methods to present a consistent framework in a notation that facilitates learning and highlights relationships between topics. This text was developed specifically to be accessible to senior level undergraduates in engineering and computer science, and includes supporting exercises to reinforce the lessons of each section. Practitioners will value Kelly's perspectives on practical applications of these principles. Complex subjects are reduced to implementable algorithms extracted from real systems wherever possible, to enhance the real-world relevance of the text.
Why Does Google Need So Many Robots?
To Jump From The Web To The Real World
Original Article: techcrunch
Why does Google need robots? Because it already rules your pocket. The mobile market, except for the slow rise of wearables, is saturated. There are millions of handsets around the world, each one connected to the Internet and most are running either Android or iOS. Except for incremental updates to the form, there will be few innovations coming out of the mobile space in the next decade.
Then there’s Glass. These devices bring the web to the real world by making us the carriers. Google is already in front of us on our small screens but Glass makes us a captive audience. By depending on Google’s data for our daily interactions, mapping, and restaurant recommendations – not to mention the digitization of our every move – we become some of the best Google consumers in history. But that’s still not enough.
Google is limited by, for lack of a better word, meat. We are poor explorers and poor data gatherers. We tend to follow the same paths every day and, like ants, we rarely stray far from the nest. Google is a data company and needs far more data than humans alone can gather. Robots, then will be the driver for a number of impressive feats in the next few decades including space exploration, improved mapping techniques, and massive changes in the manufacturing workspace.
Robots like Baxter will replace millions of expensive humans – a move that I suspect will instigate a problematic rise of unemployment in the manufacturing sector – and companies like manufacturing giant Foxconn are investing in robotics at a clip. Drones, whether human-control or autonomous, are a true extension of our senses, placing us and keeping us apprised of situations far from home base. Home helpers will soon lift us out of bed when we’re sick, help us clean, and assist us near the end of our lives. Smaller hardware projects will help us lose weight and patrol our streets. The tech company not invested in robotics today will find itself far behind the curve in the coming decade.
That’s why Google needs robots. They will place the company at the forefront of man-machine interaction in the same way that Android put them in front of millions of eyeballs. Many pundits saw no reason for Google to start a mobile arm back when Android was still young. They were wrong. The same will be the case for these seemingly wonky experiments in robotics.
Did Google buy Boston Dynamics and seven other robotics companies so it could run a thousand quadrupedal Big Dogs through our cities? No, but I could see them using BD’s PETMAN, a bipedal robot that can walk and run over rough terrain – to assist in mapping difficult-to-reach areas. It could also become a sort of Google Now for the real world, appearing at our elbows in the form of an assistant that follows us throughout the day, keeping us on track, helping with tasks, and becoming our avatars when we can’t be in two places at once. The more Google can mediate our day-to-day experience the more valuable it becomes.
Need more proof? [Read More]
Saturday, December 14, 2013
Google buys Boston Dynamics, maker of spectacular and terrifying robots
Google has acquired robotics engineering company Boston Dynamics, best known for its line of quadrupeds with funny gaits and often mind-blowing capabilities. Products that the firm has demonstrated in recent years include BigDog, a motorized robot that can handle ice and snow, the 29 mile-per-hour Cheetah, and an eerily convincing humanoid known as PETMAN. News of the deal was reported on Friday by The New York Times, which says that the Massachusetts-based company's role in future Google projects is currently unclear.
Specific details about the price and terms of the deal are currently unknown, though Google told the NYT that existing contracts — including a $10.8 million contract inked earlier this year with the US Defense Agency Research Projects Agency (DARPA) — would be honored. Despite the DARPA deal, Google says it doesn't plan to become a military contractor "on its own," according to the Times.
Boston Dynamics began as a spinoff from the Massachusetts Institute of Technology in 1992, and quickly started working on projects for the military. Besides BigDog, that includes Cheetah, an animal-like robot developed to run at high speeds, which was followed up by a more versatile model called WildCat. It's also worked on Atlas, a humanoid robot designed to work outdoors.
In a tweet, Google's Andy Rubin — who formerly ran Google's Android division — said the "future is looking awesome."
Tuesday, December 10, 2013
My plan for a content based image search
I saw this job posting from EyeEm, a photo sharing app / service, in which they express their wish/plan to build a search engine that can ‘identify and understand beautiful photographs’. That got me thinking about how I would approach building a system like that.
Here is how I would start:
1. Define what you are looking for
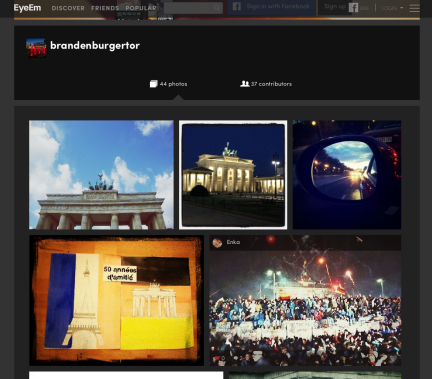
EyeEm already has a search engine based on tags and geo-location. So I assume, they want to prevent low quality pictures to appear in the results and add missing tags to pictures, based on the image’s content. One could also group similar looking pictures or rank those pictures lower which “don’t contain their tags”. For instance for the Brandenburger Torthere are a lot of similar looking pictures and even some that don’t contain the gate at all.
But for which concepts should one train the algo-rithms? Modern image retrieval systems are trained for hundreds of concepts, but I don’t think it is wise to start with that many. Even the most sophisticated, fine tuned systems have high error rates for most of the concepts as can be seen in this year’s results of the Large Scale Visual Recognition Challenge.
For instance the team from EUVision / University of Amsterdam, placed 6 in the classification challenge, only selected 16 categories for their consumer app Impala. For a consumer application I think their tags are a good choice:
- Architecture
- Babies
- Beaches
- Cars
- Cats (sorry, no dogs)
- Children
- Food
- Friends
- Indoor
- Men
- Mountains
- Outdoor
- Party life
- Sunsets and sunrises
- Text
- Women
But of course EyeEm has the luxury of looking at their log files to find out what their users are actually searching for.
And on a comparable task of classifying pictures into 15 scene categories a team from MIT under Antonio Torralba showed that even with established algorithms one can achieve nearly 90% accuracy [Xiao10]. So I think it’s a good idea to start with a limited number of standard and EyeEm specific concepts, which allows for usable recognition accuracy even with less sophisticated approaches.
But what about identifying beautiful photographs? I think in image retrieval there is no other concept which is more desirable and challenging to master. What does beautiful actually mean? What features make a picture beautiful? How do you quantify these features? Is beautiful even a sensibly concept for image retrieval? Might it be more useful trying to predict which pictures will be `liked` or `hearted` a lot? These questions have to be answered before one can even start experimenting. I think for now it is wise to start with just filtering out low quality pictures and to try to predict what factors make a picture popular.
Brand Spankin' New Vision Papers from ICCV 2013
Article from tombone's blog
This year, at ICCV 2013 in Sydney, Australia, the vision community witnessed lots of grand new ideas, excellent presentations, and gained new insights which are likely to influence the direction of vision research in the upcoming decade.

3D data is everywhere. Detectors are not only getting faster, but getting stylish. Edges are making a comeback. HOGgles let you see the world through the eyes of an algorithm. Computers can automatically make your face pictures more memorable. And why ever stop learning, when you can learn all day long?
Here is a breakdown of some of the must-read ICCV 2013 papers which I'd like to share with you:
From Large Scale Image Categorization to Entry-Level Categories, Vicente Ordonez, Jia Deng, Yejin Choi, Alexander C. Berg, Tamara L. Berg, ICCV 2013.

This paper is the Marr Prize winning paper from this year's conference. It is all about entry-level categories - the labels people will use to name an object - which were originally defined and studied by psychologists in the 1980s. In the ICCV paper, the authors study entry-level categories at a large scale and learn the first models for predicting entry-level categories for images. The authors learn mappings between concepts predicted by existing visual recognition systems and entry-level concepts that could be useful for improving human-focused applications such as natural language image description or retrieval. NOTE: If you haven't read Eleanor Rosch's seminal 1978 paper, The Principles of Categorization, do yourself a favor: grab a tall coffee, read it and prepare to be rocked.
Monday, December 9, 2013
OpenROV
OpenROV is a open-source underwater robot. But it's so much more. It's also a community of people who are working together to create more accessible, affordable, and awesome tools for underwater exploration.

The backbone of the project is the global community of DIY ocean explorers who are working, tinkering and improving the OpenROV design. The community ranges from professional ocean engineers to hobbyists, software developers to students. It's a welcoming community and everyone's feedback and input is valued.
Saturday, December 7, 2013
Google Puts Money on Robots, Using the Man Behind Android
PALO ALTO, Calif. — In an out-of-the-way Google office, two life-size humanoid robots hang suspended in a corner.
If Amazon can imagine delivering books by drones, is it too much to think that Google might be planning to one day have one of the robots hop off an automated Google Car and race to your doorstep to deliver a package?
Google executives acknowledge that robotic vision is a “moonshot.” But it appears to be more realistic than Amazon’s proposed drone delivery service, which Jeff Bezos, Amazon’s chief executive, revealed in a television interview the evening before one of the biggest online shopping days of the year.
Over the last half-year, Google has quietly acquired seven technology companies in an effort to create a new generation of robots. And the engineer heading the effort is Andy Rubin, the man who built Google’s Android software into the world’s dominant force in smartphones.
The company is tight-lipped about its specific plans, but the scale of the investment, which has not been previously disclosed, indicates that this is no cute science project.
At least for now, Google’s robotics effort is not something aimed at consumers. Instead, the company’s expected targets are in manufacturing — like electronics assembly, which is now largely manual — and competing with companies like Amazon in retailing, according to several people with specific knowledge of the project.
A realistic case, according to several specialists, would be automating portions of an existing supply chain that stretches from a factory floor to the companies that ship and deliver goods to a consumer’s doorstep.
“The opportunity is massive,” said Andrew McAfee, a principal research scientist at the M.I.T. Center for Digital Business. “There are still people who walk around in factories and pick things up in distribution centers and work in the back rooms of grocery stores.”
Google has recently started experimenting with package delivery in urban areas with its Google Shopping service, and it could try to automate portions of that system. The shopping service, available in a few locations like San Francisco, is already making home deliveries for companies like Target, Walgreens and American Eagle Outfitters.
Perhaps someday, there will be automated delivery to the doorstep, which for now is dependent on humans.
“Like any moonshot, you have to think of time as a factor,” Mr. Rubin said. “We need enough runway and a 10-year vision.”
Mr. Rubin, the 50-year-old Google executive in charge of the new effort, began his engineering career in robotics and has long had a well-known passion for building intelligent machines. Before joining Apple Computer, where he initially worked as a manufacturing engineer in the 1990s, he worked for the German manufacturing company Carl Zeiss as a robotics engineer.
“I have a history of making my hobbies into a career,” Mr. Rubin said in a telephone interview. “This is the world’s greatest job. Being an engineer and a tinkerer, you start thinking about what you would want to build for yourself.”
He used the example of a windshield wiper that has enough “intelligence” to operate when it rains, without human intervention, as a model for the kind of systems he is trying to create. That is consistent with a vision put forward by the Google co-founder Larry Page, who has argued that technology should be deployed wherever possible to free humans from drudgery and repetitive tasks.
The veteran of a number of previous Silicon Valley start-up efforts and twice a chief executive, Mr. Rubin said he had pondered the possibility of a commercial effort in robotics for more than a decade. He has only recently come to think that a range of technologies have matured to the point where new kinds of automated systems can be commercialized.
Earlier this year, Mr. Rubin stepped down as head of the company’s Android smartphone division. Since then he has convinced Google’s founders, Sergey Brin and Mr. Page, that the time is now right for such a venture, and they have opened Google’s checkbook to back him. He declined to say how much the company would spend. Read More
Wednesday, December 4, 2013
Google Compute Engine is now Generally Available with expanded OS support, transparent maintenance, and lower prices
http://googlecloudplatform.blogspot.gr/2013/12/google-compute-engine-is-now-generally-available.html
Google Cloud Platform gives developers the flexibility to architect applications with both managed and unmanaged services that run on Google’s infrastructure. We’ve been working to improve the developer experience across our services to meet the standards our own engineers would expect here at Google.
Today, Google Compute Engine is Generally Available (GA), offering virtual machines that are performant, scalable, reliable, and offer industry-leading security features like encryption of data at rest. Compute Engine is available with 24/7 support and a 99.95% monthly SLA for your mission-critical workloads. We are also introducing several new features and lower prices for persistent disks and popular compute instances.
Expanded operating system support
During Preview, Compute Engine supported two of the most popular Linux distributions, Debian and Centos, customized with a Google-built kernel. This gave developers a familiar environment to build on, but some software that required specific kernels or loadable modules (e.g. some file systems) were not supported. Now you can runany out-of-the-box Linux distribution (including SELinux and CoreOS) as well as any kernel or software you like, including Docker, FOG, xfs and aufs. We’re also announcing support for SUSE and Red Hat Enterprise Linux (in Limited Preview) and FreeBSD.
Transparent maintenance with live migration and automatic restart
At Google, we have found that regular maintenance of hardware and software infrastructure is critical to operating with a high level of reliability, security and performance. We’re introducing transparent maintenance that combines software and data center innovations with live migration technology to perform proactive maintenance while your virtual machines keep running. You now get all the benefits of regular updates and proactive maintenance without the downtime and reboots typically required. Furthermore, in the event of a failure, we automatically restart your VMs and get them back online in minutes. We’ve already rolled out this feature to our US zones, with others to follow in the coming months.
New 16-core instances
Developers have asked for instances with even greater computational power and memory for applications that range from silicon simulation to running high-scale NoSQL databases. To serve their needs, we’re launching three new instance types in Limited Preview with up to 16 cores and 104 gigabytes of RAM. They are available in the familiar standard, high-memory and high-CPU shapes.
Faster, cheaper Persistent Disks
Building highly scalable and reliable applications starts with using the right storage. Our Persistent Disk service offers you strong, consistent performance along with much higher durability than local disks. Today we’re lowering the price of Persistent Disk by 60% per Gigabyte and dropping I/O charges so that you get a predictable, low price for your block storage device. I/O available to a volume scales linearly with size, and the largest Persistent Disk volumes have up to 700% higher peak I/O capability. You can read more about the improvements to Persistent Disk in our previous blog post.
10% Lower Prices for Standard Instances
We’re also lowering prices on our most popular standard Compute Engine instances by 10% in all regions.
Customers and partners using Compute Engine
In the past few months, customers like Snapchat, Cooladata, Mendelics, Evite and Wix have built complex systems on Compute Engine and partners like SaltStack, Wowza, Rightscale, Qubole, Red Hat, SUSE, and Scalrhave joined our Cloud Platform Partner Program, with new integrations with Compute Engine.
“We find that Compute Engine scales quickly, allowing us to easily meet the flow of new sequencing requests… Compute Engine has helped us scale with our demands and has been a key component to helping our physicians diagnose and cure genetic diseases in Brazil and around the world.”
- David Schlesinger, CEO of Mendelics
"Google Cloud Platform provides the most consistent performance we’ve ever seen. Every VM, every disk, performs exactly as we expect it to and gave us the ability to build fast, low-latency applications."
- Sebastian Stadil, CEO of Scalr
We’re looking forward to this next step for Google Cloud Platform as we continue to help developers and businesses everywhere benefit from Google’s technical and operational expertise. Below is a short video that explains today’s launch in more detail.
http://googlecloudplatform.blogspot.gr/2013/12/google-compute-engine-is-now-generally-available.html
Tuesday, December 3, 2013
Copycat Russian android prepares to do the spacewalk
This robot is looking pretty pleased with itself – and wouldn't you be, if you were off to the International Space Station? Prototype cosmobot SAR-401, with its human-like torso, is designed to service the outside of the ISS by mimicking the arm and finger movements of a human puppet-master indoors.
In this picture, that's the super-focussed guy in the background but in space it would be a cosmonaut operating from the relative safety of the station's interior and so avoiding a risky spacewalk. You can watch the Russian android mirroring a human here.
SAR-1 joins a growing zoo of robots in space. NASA already has its ownRobonaut on board the ISS to carry out routine maintenance tasks. It was recently joined by a small, cute Japanese robot, Kirobo, but neither of the station's droids are designed for outside use.
Until SAR-401 launches, the station's external Dextre and Canadarm2 rule the orbital roost. They were commemorated on Canadian banknotes this year – and they don't even have faces.
Affdex Facial Coding
 Marketers recognize that emotion drives brand loyalty and purchase decisions. Yet, traditional ways of measuring emotional response - surveys and focus groups - create a gap by requiring viewers to think about and say how they feel. Neuroscience provides insight into how the mind works, but it typically requires expensive, bulky equipment and lab-type settings that limit and influence the experience.
Marketers recognize that emotion drives brand loyalty and purchase decisions. Yet, traditional ways of measuring emotional response - surveys and focus groups - create a gap by requiring viewers to think about and say how they feel. Neuroscience provides insight into how the mind works, but it typically requires expensive, bulky equipment and lab-type settings that limit and influence the experience.
Affdex is an award-winning neuromarketing tool that reads emotional states such as liking and attention from facial expressions using an ordinary webcam...to give marketers faster, more accurate insight into consumer response to brands, advertising and media. It uses automated facial expression analysis recognition, also called facial coding, to analyze your face and interpret your emotional state. Offered as a cloud-based software-as-a-service, Affdex is a fast, easy and affordable to add into existing studies. MIT-spinoff Affectiva has some of the best and brightest emotion experts behind the Affdex platform science, providing the most accurate measurement today. This ongoing investment in research and development is focused not just on measuring, but also on predicting...which ads will really work to drive sales and build brands.
Saturday, November 30, 2013
5 cool robots the EU is funding
It's EU Robotics Week time again. For the third consecutive year, the achievements of Europe's researchers and inventors working in robotics are celebrated in over 300 events from November 25th to December 1st. Here are some examples of the best EU-funded Robotics projects.

RoboHow – Can a robot learn to make pancakes on its own?
A robot that can make pancakes doesn't seem different from a bread machine. But, a robot that has learnt by itself to make pancakes, fold laundry, throw away garbage and do other everyday activities around the house is entirely different.
The project enables robots to learn on their own how to carry out tasks in human working and living environments by finding instructions online or by observing humans doing them. The goal is to develop robots that can help people in everyday activities, as well as to find out to what extent a robot can learn by itself. Robohow allows robots to load the instructions they receive into their knowledge base. However, a lot of information is still missing, so these instructions are combined with information from videos showing humans perform the tasks in question and from kinaesthetic teaching and imitation learning. The project is led by Universität Bremen, with the participation of researchers from France, Sweden, Belgium, The Netherlands, Greece, Germany and Switzerland. See the video & the website.
RADHAR – Self-Driving
Driving a wheelchair can be difficult and very tiring. As a result, the user may over-steer the wheelchair or not have enough strength to steer it. The RADHAR (Robotic ADaptation to Humans Adapting to Robots) project has developed an intelligent wheelchair that enables people with cognitive or physical challenges to independently drive around in an everyday-life environment.
Researchers from Belgium, Germany, Austria, Sweden & Switzerland have developed an intelligent system with advanced sensors, which allow the wheelchair to identify, interpret and correct confusing or weak signals from the driver and to help the wheelchair user navigate in various environments. The driver of the wheelchair is able to decide how much help he or she needs. Meanwhile, the robot can correct the projected path using information from online 3D-laser sensors reading the terrain. It is also equipped with cameras monitoring the position of the user in order to be able to judge if he or she is awake and in control. The robot takes in information on the surroundings, the position and the focus of attention of the driver; it then adjusts the path avoiding dangers, such as steps or obstacles. The robot also has haptic sensors in the joystick; they use tactile feedback sensing the touch of the user to measure how much force is being used. It then uses all the sensors together to interpret the user's intention and the environment and is then able to either make small corrections in steering or to take more control and navigate the wheelchair around safely.
The RADHAR project, which just finished after three years, was led by Katholieke Universiteit Leuven. Find out more in RADHAR website.
Stiff-Flop - A Surgical Robot based on an Elephant's Trunk
During the European Robotics Week, at the Science Museum in London we'll meet swimming, flapping or crawling robots mimicking real animals.
The EU-funded Stiff-Flop project will be showing a robotic arm inspired by the softness and agility of an elephant's trunk and by the octopus' ability to find food by exploring small cavities in rocks.

This robotic arm could be used in keyhole surgery, as it is able to adjust its texture and stiffness to organs inside the human body; it can soften to get through narrow passages and then stiffen again when needed avoiding damage to soft tissue. It also has a gripper at the edge and is able to learn and develop how to manipulate soft objects in the human body, through interaction with a human instructor. This project could make keyhole surgery safer and minimise post-operative pain and scarring.
The consortium led by King's College London is made up of researchers from the United Kingdom, Spain, Italy, Poland, Germany, The Netherlands and Israel and supported by the European Commission 7.4 m euros out of a total estimated cost of 9.6 m euros). Find out more here.
ROBOFOOT – Robots bring manufacturing back to Europe
The industry for hand-made fashion shoes is one of the important industries in Europe, which faced intense competition from low-cost countries. The EU-funded ROBOFOOT project showed that robots can also be introduced in traditional footwear industry, maintaining most of the current production facilities and help Europe's footwear industry. Starting in September 2010 and ending in February 2013, a consortium of 10 partners from Spain, Italy and Germany led by Fundación Tekniker have been developing the technology and the results have been implemented in a set of relevant manufacturing operations. The project had 2.6 m euros of EU funding (out of a total cost of 3.7 m euros).
Robots are still not widely used in the footwear industry, which amounts to more than 26.000 companies and almost 400.000 employees in Europe. The introduction of robotics will help overcome the complexity inautomation processes. The ROBOFOOT project has developed robots using laser sensors to identify the shoe and its position. The robots are able to work with soft materials and can grasp, handle and packageshoes without damaging them and at the same time taking on dangerous jobs, such as inking the shoes, while supervised by humans. Find out more in this video and in the Robofoot website.
STRANDS - The Last Robot Standing Wins!
A robot marathon will take place during European Robotics Week in the UK, Sweden, Germany and Austria. Robots will battle it out to be the last one standing in the STRANDS Robot Marathon; the challenge is for them to autonomously patrol a populated environment for as long as possible, covering the most distance in the shortest time possible.

STRANDS is an EU-funded project enabling robots to achieve robust and intelligent behaviour in human environments. STRANDS robots will be evaluated in a care home for the elderly in Austria (assisting human carers), and in an office environment patrolled by a security firm in the UK. STRANDS is developing a complete cognitive system, which will use and exploit long-term experiences, learning and adapting from memory. The approach is based on understanding 3D space and how it changes over time, from milliseconds to months. Researchers from the United Kingdom, Sweden, Austria and Germany contribute to this project.
The robots developed by STRANDS will be able to run for significantly longer than current systems. Runtime has been a huge roadblock in the development of autonomous robots until now. Long runtimes provide previously unattainable opportunities for a robot to learn about its world. Society will benefit as robots become more capable of assisting humans, a necessary advance due to the demographic shifts in our society.
Find out more on Strands in this video, in this article and in the project website.
Background
During European Robotics Week (November 25 - December 1, 2013), various robotics-related activities across Europe will highlight the growing importance of robotics in a wide variety of fields. Businesses, universities, museums and research centres participate in activities aimed at the general public (school visits with lectures on robotics, guided tours for pupils, open labs, exhibitions, challenges and robots in action in public squares).The Week should raise awareness of recent achievements in robotics in Europe and inspire Europe's youth to pursue a career in science.
The European Commission funds over 100 collaborative projects under the 7th Framework Programme on advanced research into robots. The projects aim at helping robots better understand the world around them through sensing, perception, understanding, reasoning and action. The projects cover subjects ranging from autonomy, manipulation / grasping, mobility and navigation in all terrains, to human-robot interaction and cooperative robots. Many, if not all, of the projects tackle seemingly simple tasks which are very difficult for machines: how to pick up a ball, avoid bumping into a wall, recognize a danger in the home and so on.
Sunday, November 17, 2013
11th International conference on cellular automata for research and industry - ACRI 2014
Krakow, Poland, September 22-25, 2014
http://acri2014.agh.edu.pl
Cellular automata (CA) present a very powerful approach to the study of spatio-temporal systems where complex phenomena build up out of many simple local interactions. They account often for real phenomena or solutions of problems, whose high complexity could unlikely be formalised in different contexts. Furthermore parallelism and locality features of CA allow a straightforward and extremely easy parallelisation, therefore an immediate implementation on parallel computing resources. These characteristics of the CA research resulted in the formation of interdisciplinary research teams. These teams produce remarkable research results and attract scientists from different fields. The main goal of the 10th edition of ACRI 2012 Conference (Cellular Automata for Research and Industry) is to offer both scientists and engineers in academies and industries an opportunity to express and discuss their views on current trends, challenges, and state-of-the art solutions to various problems in the fields of arts, biology, chemistry, communication, cultural heritage, ecology, economy, geology, engineering, medicine, physics, sociology, traffic control, etc.
Topics of either theoretical or applied interest about CA and CA-based models and systems include but are not limited to:
-
Algebraic properties and generalization
-
Complex systems
-
Computational complexity
-
Dynamical systems
-
Hardware circuits, architectures, systems and applications
-
Modeling of biological systems
-
Modeling of physical or chemical systems
-
Modeling of ecological and environmental systems
-
Image Processing and pattern recognition
-
Natural Computing
-
Quantum Cellular Automata
-
Parallelism
Submissions
Authors are invited to submit papers presenting their original and unpublished research. Papers should not exceed 10 pages and should be formatted according to the usual LNCS article style (http://www.springer.com/computer/lncs). Details on the electronic submission procedure will be provided through the website of the conference (http://acri2014.agh.edu.pl).
Publication
A volume of proceedings will be published by Springer-Verlag in the Lecture Notes in Computer Science series and will be available by the time of the conference. After the conference, refereed volumes of selected proceedings containing extended papers will be organized as special issues of ISI international journals like Journal of Cellular Automata.
Important dates
-
Paper submission: March 19, 2014
-
Notification of paper acceptance or rejection: April 22, 2014
-
Final version of the paper for the proceedings: May 14, 2014
-
Conference: September 22-25, 2014
Conference location
ACRI2014 will be held at AGH University of Science and Technology, Kraków, Poland.
AGH University of Science and Technology is one of the leading technical universities in Poland. The AGH University was established in 1919, serves the science and industry through education, as well as research and development. Krakow is the second largest city in Poland, known as “cultural capital of Poland” and “a city of tradition” and a city of a unique medieval architecture. Krakow is registered on the UNESCO World Heritage List and awarded the title of the European Capital of Culture in 2000. Krakow as such a very popular touristic destination is served by convenient air, road and rail connections.
Thursday, November 14, 2013
Paper Keyboard: Type on a real piece of paper
 Are you tired of typing on your screen? Forget bluetooth, use paper! Just print a PDF file on paper and use it as a keyboard. How? Put your phone where marked on the paper and see how the magic happens: the phone’s camera detects your fingers with state of the art algorithms. You can play games, chat with friends, send emails, write anything with the keyboard. With the free version you can play 2 games, additional features may be available with in-app purchase.
Are you tired of typing on your screen? Forget bluetooth, use paper! Just print a PDF file on paper and use it as a keyboard. How? Put your phone where marked on the paper and see how the magic happens: the phone’s camera detects your fingers with state of the art algorithms. You can play games, chat with friends, send emails, write anything with the keyboard. With the free version you can play 2 games, additional features may be available with in-app purchase.
Now all games are free for 2 days! Don't miss this opportunity!
Features:
• Use a piece of paper as a keyboard
The app works on letter-size and A4 paper as well!
• Several games are available in the app
Collect the letters of quotes, typing games, ball games etc.
• Built-in chat client
You can chat with your friends with the keyboard using several platforms
• Send emails directly from the app
Are you tired of typing a long email to your colleague? Use the app and the keyboard!
• Write anything and paste the text into any app
Use the paper keyboard and paste your text in any text editor to format.
https://itunes.apple.com/us/app/paper-keyboard-type-on-real/id715319520
Wednesday, November 13, 2013
This morphing table can create a virtual version of you in realtime
Keiichi Matsuda is excited about this invention and I can't blame him: A solid table that reproduces a virtual version of anything that you put under its sensors—in realtime. You can see how it reproduces the hands moving in the clip above, but there's more:
Created by Professor Hiroshi Ishii and his students at the MIT Media Lab, this tangible interfacestarts with cameras that capture objects in three dimensions. The 3D information is processed by a computer, which then moves the solid rods that form the center of the table. The result is a 3D replica of your hands.
The system would allow people to reproduce objects remotely and, of course, you can feed it any 3D data, including city maps.
Article from http://sploid.gizmodo.com/this-morphing-table-can-create-a-virtual-version-of-you-1458375473
RS4 - Self balancing Raspberry Pi image processing Robot
Read all the details about this project Here
Monday, November 11, 2013
Real Time Navigation System
The aim of this diploma thesis is the study and the implementation of modern theories and methods of computer vision in a real robotic vehicle. In this framework, the robotic vehicle SRV-1 of ACS Lab was used. Its communication with a computer was achieved and the wireless transfer of commands, data, images, videos and sensor data makes possible the realization. By using the received data, the robotic vehicle is capable of navigating autonomously in the real world. It realizes obstacles and understands the visual content of images. This perception is due to the creation of visual content descriptor synthesized in real time. The descriptor's components are the local features of the image, which are in the sequel used for image retrieval. Furthermore, another method that is able to perform the robotic vehicle is automatic panorama composition.
For more details please contact Antonio Arvanitidis <antoarva<at>gmail.com>
Sunday, November 10, 2013
Impala
Impala is the first app in the world that automatically sorts the photos on your phone. You do not have to manually label each and every one of them: Impala “looks” into your images and videos and recognizes what’s inside. For instance, Impala can recognize cats, sunsets, beaches, and so on. Impala then automatically creates photo albums and organizes your photos. For privacy: You’re good. The app does not connect or transmit any of your data to cloud services.


https://itunes.apple.com/us/app/impala/id736620048?ls=1&mt=8
[via http://www.ceessnoek.info/]
Wednesday, November 6, 2013
Dedicated to me…from my Friends!!!!!
This blog is online for more than 4 years. This is the first time I want to share something personal with you. Today is my birthday, and my colleagues and friends gave me a very precious gift…I want to share this gift with you… Thank you: Nektarios, Zagorito, Lazaros, Georgiakis, Vaggelis, Chrysa, Christina, Kapoutsaros, Vasia, Antonios, Korkas and GOGO!!!!
Wednesday, October 30, 2013
CfP: ACM MMSys 2014 Dataset Track
The ACM Multimedia Systems conference (http://www.mmsys.org) provides a forum for researchers, engineers, and scientists to present and share their latest research findings in multimedia systems. While research about specific aspects of multimedia systems is regularly
published in the various proceedings and transactions of the networking, operating system, real-time system, and database communities, MMSys aims to cut across these domains in the context of multimedia data types. This provides a unique opportunity to view the intersections and interplay of the various approaches and solutions developed across these domains to deal with multimedia data types.
Furthermore, MMSys provides an avenue for communicating research that addresses multimedia systems holistically. As an integral part of the conference since 2012, the Dataset Track provides an opportunity for researchers and practitioners to make their work available (and citable) to the multimedia community. MMSys encourages and recognizes dataset sharing, and seeks contributions in all areas of multimedia (not limited to MM systems). Authors publishing datasets will benefit by increasing the public awareness of their effort in collecting the datasets.
In particular, authors of datasets accepted for publication will receive:
- Dataset hosting from MMSys for at least 5 years
- Citable publication of the dataset description in the proceedings published by ACM
- 15 minutes oral presentation time at the MMSys 2014 Dataset Track
All submissions will be peer-reviewed by at least two members of the technical program committee of the MMSys 2014. Datasets will be evaluated by the committee on the basis of the collection methodology and the value of the dataset as a resource for the research community.
Submission Guidelines
Authors interested in submitting a dataset should:
1. Make their data available by providing a public URL for download
2. Write a short paper describing
a. motivation for data collection and intended use of the data set,
b. the format of the data collected,
c. the methodology used to collect the dataset, and
d. basic characterizing statistics from the dataset.
Papers should be at most 6 pages long (in PDF format) prepared in the ACM style and written in English.
Submission site: http://liubei.ddns.comp.nus.edu.sg/mmsys2014-dataset/
Important dates
* Data set paper submission deadline: November 11, 2013
* Notification: December 20, 2013
* MMSys conference : March 19 - 21, 2014
** MMsys Datasets **
Previous accepted datasets can be accessed at
http://traces.cs.umass.edu/index.php/MMsys/MMsys
For further queries and extra information, please contact us at
mlux<at>itec<dot>uni-klu<dot>ac<dot>at
Monday, October 28, 2013
CBMI 2014
Following the eleven successful previous events of CBMI (Toulouse 1999, Brescia 2001, Rennes 2003, Riga 2005, Bordeaux 2007, London 2008, Chania 2009, Grenoble 2010, Madrid 2011, Annecy 2012, and Veszprem 2013), It is our pleasure to welcome you to CBMI 2014, the 12th International Content Based Multimedia Indexing Workshop , in Klagenfurt, Austria on June 18-20 2014.
The 12th International CBMI Workshop aims at bringing together the various communities involved in all aspects of content-based multimedia indexing, retrieval, browsing and presentation. The scientific program of CBMI 2014 will include invited keynote talks and regular, special and demo sessions with contributed research papers.
We sincerely hope that a carefully crafted program, the scientific discussions that the workshop will hopefully stimulate, and your additional activities in Klagenfurt and its surroundings, most importantly the lovely Lake Wörthersee, will make your CBMI 2014 participation worthwhile and a memorable experience.
Important dates:
Paper submission deadline: February 16, 2014
Notification of acceptance: March 30, 2014
Camera-ready papers due: April 14, 2014
Author registration: April 14, 2014
Early registration: May 25, 2014
Friday, October 25, 2013
LIRE presentation at the ACM Multimedia Open Source Software Competition 2013
LIRE Solr [http://www.semanticmetadata.net/]
The Solr plugin itself is fully functional for Solr 4.4 and the source is available at https://bitbucket.org/dermotte/liresolr. There is a markdown document README.md explaining what can be done with plugin and how to actually install it. Basically it can do content based search, content based re-ranking of text searches and brings along a custom field implementation & sub linear search based on hashing.
Thursday, October 24, 2013
ACM Multimedia 2013 Open Source Competition winner is….
Essentia!!! Congratulations!!!!
Essentia 2.0 beta, is an open-source C++ library for audio analysis and audio-based music information retrieval released under the Affero GPLv3 license (also available underproprietary license upon request). It contains an extensive collection of reusable algorithmswhich implement audio input/output functionality, standard digital signal processing blocks, statistical characterization of data, and a large set of spectral, temporal, tonal and high-level music descriptors. In addition, Essentia can be complemented with Gaia, a C++ library with python bindings which implement similarity measures and classifications on the results of audio analysis, and generate classification models that Essentia can use to compute high-level description of music (same license terms apply).
Essentia is not a framework, but rather a collection of algorithms (plus some infrastructure for multithreading and low memory usage) wrapped in a library. It doesn’t provide common high-level logic for descriptor computation (so you aren’t locked into a certain way of doing things). It rather focuses on the robustness, performance and optimality of the provided algorithms, as well as ease of use. The flow of the analysis is decided and implemented by the user, while Essentia is taking care of the implementation details of the algorithms being used. An example extractor is provided, but it should be considered as an example only, not “the” only correct way of doing things.

The library is also wrapped in Python and includes a number of predefined executable extractors for the available music descriptors, which facilitates its use for fast prototyping and allows setting up research experiments very rapidly. Furthermore, it includes a Vamp plugin to be used with Sonic Visualiser for visualization purposes. The library is cross-platform and currently supports Linux, Mac OS X, and Windows systems. Essentia is designed with a focus on the robustness of the provided music descriptors and is optimized in terms of the computational cost of the algorithms. The provided functionality, specifically the music descriptors included in-the-box and signal processing algorithms, is easily expandable and allows for both research experiments and development of large-scale industrial applications.
2 honorable mentions are OpenSMILE and SSI
List all the open source projects presented at the ACM Multimedia conference
ACM Multimedia 2013 best paper award goes to….
ACM Multimedia 2013 best paper award goes to Attribute-augmented Semantic Hierarchy for Image Retrieval
This paper presents a novel Attribute-augmented Semantic Hierarchy (A2 SH) and demonstrates its effectiveness in bridging both the semantic and intention gaps in Content-based Image Retrieval (CBIR). A2 SH organizes the semantic concepts into multiple semantic levels and augments each concept with a set of related attributes, which describe the multiple facets of the concept and act as the intermediate bridge connecting the concept and low-level visual content. A hierarchical semantic similarity function is learnt to characterize the semantic similarities among images for retrieval. To better capture user search intent, a hybrid feedback mechanism is developed, which collects hybrid feedbacks on attributes and images. These feedbacks are then used to refine the search results based on A2 SH. We develop a content-based image retrieval system based on the proposed A2 SH. We conduct extensive experiments on a large-scale data set of over one million Web images. Experimental results show that the proposed A2 SH can characterize the semantic affinities among images accurately and can shape user search intent precisely and quickly, leading to more accurate search results as compared to state-of-the-art CBIR solutions.
Wednesday, October 23, 2013
Novaemötions dataset
This dataset contains the facial expression images captured using the novaemötions game. It contains over 40,000 images, labeled with the challenged expression and the expression recognized by the game algorithm, augmented with labels obtained through crowdsourcing.
If you are interested in obtaining the dataset, contact a.mourao@campus.fct.unl.pt

Tuesday, October 22, 2013
GRIRE paper is now available online (open access to everyone)
Golden Retriever Image Retrieval Engine (GRire) is an open source light weight Java library developed for Content Based Image Retrieval (CBIR) tasks, employing the Bag of Visual Words (BOVW) model. It provides a complete framework for creating CBIR system including image analysis tools, classifiers, weighting schemes etc., for efficient indexing and retrieval procedures. Its eminent feature is its extensibility, achieved through the open source nature of the library as well as a user-friendly embedded plug-in system. GRire is available on-line along with install and development documentation on http://www.grire.net and on its Google Code page http://code.google.com/p/grire. It is distributed either as a Java library or as a standalone Java application, both GPL licensed.
http://dl.acm.org/citation.cfm?id=2502227&CFID=255574745&CFTOKEN=21345709
Monday, October 21, 2013
MAV Urban Localization from Google Street View Data
This approach tackles the problem of globally localizing a camera-equipped micro aerial vehicle flying within urban environments for which a Google Street View image database exists. To avoid the caveats of current image-search algorithms in case of severe viewpoint changes between the query and the database images, the authors proposed to generate virtual views of the scene, which exploit the air-ground geometry of the system. To limit the computational complexity of the algorithm, they rely on a histogram-voting scheme to select the best putative image correspondences. The proposed approach is tested on a 2km image dataset captured with a small quadroctopter flying in the streets of Zurich. The success of the approach shows
that the new air-ground matching algorithm can robustly handle extreme changes in viewpoint, illumination, perceptual aliasing, and over-season variations, thus, outperforming conventional
visual place-recognition approaches.
For more info, http://rpg.ifi.uzh.ch/docs/IROS13_Maj...
A. Majdik, Y. Albers-Schoenberg, D. Scaramuzza MAV Urban Localization from Google Street View Data, IROS'13, IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS'13, 2013.
More info at: http://rpg.ifi.uzh.ch
Friday, October 18, 2013
Wednesday, October 16, 2013
Qualcomm Zeroth - Biologicially Inspired Learning
Computer technology still lags far behind the abilities of the human brain, which has billions of neurons that help us simultaneously process a plethora of stimuli from our many senses. But Qualcomm hopes to shrink that bridge with a new type of computer architecture modeled after the brain, which would be able to learn new skills and react to inputs without needing a human to manually write any code. It's calling its new chips Qualcomm Zeroth Processors, categorized as Neural Processing Units (NPUs), and already has a suite of software tools that can teach computers good and bad behavior without explicit programming.
Qualcomm demoed its technology by creating a robot that learns to visit only white tiles on a gridded floor. The robot first explores the environment, then is given positive reinforcement while on a white tile, and proceeds to only seek out other white tiles. The robot learns to like the white tile due to a simple "good robot" command, rather than any unique algorithm or code
The computer architecture is modeled after biological neurons, which respond to the environment through a series of electrical pulses. This allows the NPU to passively respond to stimuli, waiting for neural spikes to return relevant information for a more effective communication structure. According to MIT Technology Review, Qualcomm is hoping to have a software platform ready for researchers and startups by next year.
Qualcomm isn't the only company working on building a brain-like computer system. IBM has a project known as SyNAPSE that relates to objects and ideas, rather than the typical if-this-then-that computer processing model. This new architecture would someday allow a computer to efficiently recognize a friendly face in a crowd, something that takes significant computing power with today's current technology. Modeling new technology after the human brain may be the next big evolutionary step in creating more powerful computers.
Article from http://www.theverge.com/2013/10/11/4827280/qualcomm-brain-inspired-learning-computer-chip
Thursday, October 10, 2013
Small cubes that self-assemble
Article from http://gsirak.ee.duth.gr/index.php/blog
Small cubes with no exterior moving parts can propel themselves forward, jump on top of each other, and snap together to form arbitrary shapes.
In 2011, when an MIT senior named John Romanishin proposed a new design for modular robots to his robotics professor, Daniela Rus, she said, “That can’t be done.”
Two years later, Rus showed her colleague Hod Lipson, a robotics researcher at Cornell University, a video of prototype robots, based on Romanishin’s design, in action. “That can’t be done,” Lipson said.
In November, Romanishin — now a research scientist in MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) — Rus, and postdoc Kyle Gilpin will establish once and for all that it can be done, when they present a paper describing their new robots at the IEEE/RSJ International Conference on Intelligent Robots and Systems.
Known as M-Blocks, the robots are cubes with no external moving parts. Nonetheless, they’re able to climb over and around one another, leap through the air, roll across the ground, and even move while suspended upside down from metallic surfaces.
Inside each M-Block is a flywheel that can reach speeds of 20,000 revolutions per minute; when the flywheel is braked, it imparts its angular momentum to the cube. On each edge of an M-Block, and on every face, are cleverly arranged permanent magnets that allow any two cubes to attach to each other.

A prototype of a new modular robot, with its innards exposed and its flywheel — which gives it the ability to move independently — pulled out. Photo: M. Scott Brauer
“It’s one of these things that the [modular-robotics] community has been trying to do for a long time,” says Rus, a professor of electrical engineering and computer science and director of CSAIL. “We just needed a creative insight and somebody who was passionate enough to keep coming at it — despite being discouraged.”
Embodied abstraction
As Rus explains, researchers studying reconfigurable robots have long used an abstraction called the sliding-cube model. In this model, if two cubes are face to face, one of them can slide up the side of the other and, without changing orientation, slide across its top.
The sliding-cube model simplifies the development of self-assembly algorithms, but the robots that implement them tend to be much more complex devices. Rus’ group, for instance, previously developed a modular robot called the Molecule, which consisted of two cubes connected by an angled bar and had 18 separate motors. “We were quite proud of it at the time,” Rus says.
According to Gilpin, existing modular-robot systems are also “statically stable,” meaning that “you can pause the motion at any point, and they’ll stay where they are.” What enabled the MIT researchers to drastically simplify their robots’ design was giving up on the principle of static stability.
“There’s a point in time when the cube is essentially flying through the air,” Gilpin says. “And you are depending on the magnets to bring it into alignment when it lands. That’s something that’s totally unique to this system.”
That’s also what made Rus skeptical about Romanishin’s initial proposal. “I asked him build a prototype,” Rus says. “Then I said, ‘OK, maybe I was wrong.’”
Read More http://gsirak.ee.duth.gr/index.php/blog
Geoff Hinton - Recent Developments in Deep Learning
Geoff Hinton presents as part of the UBC Department of Computer Science's Distinguished Lecture Series, May 30, 2013.
Professor Hinton was awarded the 2011 Herzberg Canada Gold Medal for Science and Engineering, among many other prizes. He is also responsible for many technological advancements impacting many of us (better speech recognition, image search, etc.)
Wednesday, October 9, 2013
Disney develops way to 'feel' touchscreen images
http://www.bbc.co.uk/news/technology-24443271
Disney researchers have found a way for people to "feel" the texture of objects seen on a flat touchscreen.
The technique involves sending tiny vibrations through the display that let people "feel" the shallow bumps, ridges and edges of an object.
The vibrations fooled fingers into believing they were touching a textured surface, said the Disney researchers.
The vibration-generating algorithm should be easy to add to existing touchscreen systems, they added.
Developed by Dr Ali Israr and colleagues at Disney's research lab in Pittsburgh, the vibrational technique re-creates what happens when a finger tip passes over a real bump.
"Our brain perceives the 3D bump on a surface mostly from information that it receives via skin stretching," said Ivan Poupyrev, head of the interaction research group in Pittsburgh.
To fool the brain into thinking it is touching a real feature, the vibrations imparted via the screen artificially stretch the skin on a fingertip so a bump is felt even though the touchscreen surface is smooth.
The researchers have developed an underlying algorithm that can be used to generate textures found on a wide variety of objects.
A video depicting the system in action shows people feeling apples, jellyfish, pineapples, a fossilised trilobite as well as the hills and valleys on a map.
The more pronounced the feature, the greater the vibration is needed to mimic its feel.
The vibration system should be more flexible than existing systems used to give tactile feedback on touchscreens, which typically used a library of canned effects, said Dr Israr.
"With our algorithm we do not have one or two effects, but a set of controls that make it possible to tune tactile effects to a specific visual artefact on the fly," he added.
Saturday, October 5, 2013
Need software libraries and tools for your research ?
Attend the ACM MM'13 Open Source Software Competition:
-
C.-Y. Huang, D.-Y. Chen, C.-H. Hsu, and K.-T. Chen: GamingAnywhere: An Open-Source Cloud Gaming Testbed
-
J. Wagner, F. Lingenfelser, T. Baur, I. Damian, F. Kistler, and E. Andre: The Social Signal Interpretation (SSI) Framework – Multimodal Signal Processing and Recognition in Real-Time
-
F. Eyben, F. Weninger, F. Groß, and B. Schuller: Recent Developments in openSMILE, the Munich Open-Source Multimedia Feature Extractor
-
I. Tsampoulatidis, D. Ververidis, P. Tsarchopoulos, S. Nikolopoulos, I. Kompatsiaris, and N. Komninos: ImproveMyCity – An open source platform for direct citizen-government communication
-
M. Lux: LIRE: Open Source Image Retrieval in Java
-
L. Tsochatzidis, C. Iakovidou, S. Chatzichristofis, and Y. Boutalis: Golden Retriever – A Java Based Open Source Image Retrieval Engine
-
R. Aamulehto, M. Kuhna, and P. Oittinen: Stage Framework – An HTML5 and CSS3 Framework for Digital Publishing
-
D. Bogdanov, N. Wack, E. Gómez, S. Gulati, P. Herrera, O. Mayor, G. Roma, J. Salamon, J. Zapata, and X. Serra: ESSENTIA: an Audio Analysis Library for Music Information Retrieval
-
C. Flynn, D. Monaghan, and N.E. O Connor: SCReen Adjusted Panoramic Effect – SCRAPE
-
H. Yviquel, A. Lorence, K. Jerbi, G. Cocherel, A. Sanchez, and M. Raulet: Orcc: Multimedia development made easy
Wednesday, September 25, 2013
Matlab implementation of CEDD
Finally, the MATLAB implementation of CEDD is available on-line.

The source code is quite simple and easy to be handled by all users. There is a main function that has the task of extracting the CEDD descriptor from a given image.
Download the Matlab implementation of CEDD (For academic purposes only)
Few words about the CEDD descriptor:
The descriptors, which include more than one features in a compact histogram, can be regarded that they belong to the family of Compact Composite Descriptors. A typical example of CCD is the CEDD descriptor. The structure of CEDD consists of 6 texture areas. In particular, each texture area is separated into 24 sub regions, with each sub region describing a color. CEDD's color information results from 2 fuzzy systems that map the colors of the image in a 24-color custom palette. To extract texture information, CEDD uses a fuzzy version of the five digital filters proposed by the MPEG-7 EHD. The CEDD extraction procedure is outlined as follows: when an image block (rectangular part of the image) interacts with the system that extracts a CCD, this section of the image simultaneously goes across 2 units. The first unit, the color unit, classifies the image block into one of the 24 shades used by the system. Let the classification be in the color $m, m \in [0,23]$. The second unit, the texture unit, classifies this section of the image in the texture area $a, a \in [0,5]$. The image block is classified in the bin $a \times 24 + m$. The process is repeated for all the image blocks of the image. On the completion of the process, the histogram is normalized within the interval [0,1] and quantized for binary representation in a three bits per bin quantization.

The most important attribute of CEDDs is the achievement of very good results that they bring up in various known benchmarking image databases. The following table shows the ANMRR results in 3 image databases. The ANMRR ranges from '0' to '1', and the smaller the value of this measure is, the better the matching quality of the query. ANMRR is the evaluation criterion used in all of the MPEG-7 color core experiments.

Download the Matlab implementation of CEDD (For academic purposes only)
Monday, September 23, 2013
A Multi-Objective Exploration Strategy for Mobile Robots under Operational Constraints

IEEE Access
Multi-objective robot exploration, constitutes one of the most challenging tasks for autonomous robots performing in various operations and different environments. However, the optimal exploration path depends heavily on the objectives and constraints that both these operations and environments introduce. Typical environment constraints include partially known or completely unknown workspaces, limited-bandwidth communications and sparse or dense clattered spaces. In such environments, the exploration robots must satisfy additional operational constraints including time-critical goals, kinematic modeling and resource limitations. Finding the optimal exploration path under these multiple constraints and objectives constitutes a challenging non-convex optimization problem. In our approach, we model the environment constraints in cost functions and utilize the Cognitive-based Adaptive Optimization (CAO) algorithm in order to meet time-critical objectives. The exploration path produced is optimal in the sense of globally minimizing the required time as well as maximizing the explored area of a partially unknown workspace. Since obstacles are sensed during operation, initial paths are possible to be blocked leading to a robot entrapment. A supervisor is triggered to signal a blocked passage and subsequently escape from the basin of cost function local minimum. Extensive simulations and comparisons in typical scenarios are presented in order to show the efficiency of the proposed approach.
Wednesday, September 18, 2013
3-Sweep: Extracting Editable Objects from a Single Photo
by Tao Chen · Zhe Zhu · Ariel Shamir · Shi-Min Hu · Daniel Cohen-Or
Abstract
We introduce an interactive technique for manipulating simple 3D shapes based on extracting them from a single photograph. Such extraction requires understanding of the components of the shape, their projections, and relations. These simple cognitive tasks for humans are particularly difficult for automatic algorithms. Thus, our approach combines the cognitive abilities of humans with the computational accuracy of the machine to solve this problem. Our technique provides the user the means to quickly create editable 3D parts— human assistance implicitly segments a complex object into its components, and positions them in space. In our interface, three strokes are used to generate a 3D component that snaps to the shape’s outline in the photograph, where each stroke defines one dimension of the component. The computer reshapes the component to fit the image of the object in the photograph as well as to satisfy various inferred geometric constraints imposed by its global 3D structure. We show that with this intelligent interactive modeling tool, the daunting task of object extraction is made simple. Once the 3D object has been extracted, it can be quickly edited and placed back into photos or 3D scenes, permitting object-driven photo editing tasks which are impossible to perform in image-space. We show several examples and present a user study illustrating the usefulness of our technique.
Tuesday, September 17, 2013
PhD Position in Multimodal Person and Social Behaviour Recognition
Application Deadline: Tue, 10/01/2013
Location: Denmark
Employer:Aalborg University
At the Faculty of Engineering and Science, Department of Electronic Systems in Aalborg, a PhD stipend in Multimodal Person and Social Behaviour Recognition is available within the general study programme Electrical and Electronic Engineering. The stipend is open for appointment from November 1, 2013, or as soon as possible thereafter. Job description The PhD student will work on the research project “Durable Interaction with Socially Intelligent Robots” funded by the Danish Council for Independent Research, Technology and Production Sciences. This project aims at developing methods to make service robots socially intelligent and capable of establishing durable relationships with their users. This relies on developing the capabilities to sense and express, which will be achieved by the fusion of sensor signals in an interactive way. The PhD student will research on technologies for vision based social behaviour recognition, person identification and person tracking in the context of human robot interaction. Multimodal fusion will be carried out in collaboration with another PhD student who will work on the same research project with a focus on array based speech processing. The successful applicant must have a Master degree in machine learning, statistical signal processing or computer vision. You may obtain further information from Associate Professor Zheng-Hua Tan, Department of Electronic Systems, phone: +45 9940 8686, email:zt@es.aau.dk , concerning the scientific aspects of the position.
Job URL: Visit the job's url
GrowMeUp
Luxand, Inc. in collaboration with Goldbar Ventures released a new application that helps children produce photos of themselves growing up. The new tool is called GrowMeUp. It’s based on Luxand’s years of experience developing biometric identification and morphing technologies.
You can license the technology used in this application for embedding in your own entertainment applications. Please reply to this email if you’re interested.
About GrowMeUp
Using GrowMeUp could not be made simpler (after all, the target audience is very young). The user will upload a picture containing their face, specify their gender and ethnicity, and choose among the many professions available. GrowMeUp will then automatically identify the face and its features, “grow it up” by applying Luxand’s proprietary aging technologies, and carefully embed the resulting “adult” face into a photo showing a working professional.
Kids will have a wide range of professions to choose from. GrowMeUp contains photos of the following persons: Astronaut, Chef, Doctor, Firefighter, Lawyer, Policeman, Musician, Teacher, Pilot, Soldier, and Model.
The app is available at Apple Store. The online version is also available to users without an iOS device at http://growmeup.com/
Tuesday, September 10, 2013
ACM International Conference on Multimedia Retrieval
ACM International Conference on Multimedia Retrieval (ICMR) Glasgow, UK, 1st - 4th April 2014 http://www.icmr2014.org/
Important dates
* October 15, 2013 – Special Session Proposals
* November 1, 2013 – Special session Selection
* December 2, 2013 – Paper Submission
* January 15, 2014 – Industrial Exhibits and multimedia Retrieval
The Annual ACM International Conference on Multimedia Retrieval (ICMR) offers a great opportunity for exchanging leading-edge multimedia retrieval ideas among researchers, practitioners and other potential users of multimedia retrieval systems. ICMR 2014 is seeking original high quality submissions addressing innovative research in the broad field of multimedia retrieval. We wish to highlight significant contributions addressing the main problem of search and retrieval but also the related and equally important issues of multimedia content management, user interaction, and community-based management. The conference will be held in Glasgow during 1-5 April 2014.
Topics of interest include, but are not limited to:
* Content- and context-based indexing, search and retrieval of images and video
* Multimedia content search and browsing on the Web
* Advanced descriptors and similarity metrics for audio, image, video and 3D data
* Multimedia content analysis and understanding
* Semantic retrieval of visual content
* Learning and relevance feedback in media retrieval
* Query models, paradigms, and languages for multimedia retrieval
* Multimodal media search
* Human perception based multimedia retrieval
* Studies of information-seeking behavior among image/video users
* Affective/emotional interaction or interfaces for image/video retrieval
* HCI issues in multimedia retrieval
* Evaluation of multimedia retrieval systems
* High performance multimedia indexing algorithms
* Community-based multimedia content management
* Applications of Multimedia Retrieval: Medicine, Multimodal Lifelogs, Satellite Imagery, etc.
* Image/video summarization and visualization
Friday, September 6, 2013
The GRIRE Library - Pack Release: Timers Pack
![]()
This pack provides components that measure the time elapsed by other ones for detailed benchmarking. It contains a component of each type that takes as argument another component of the same type and measures the time it needs for each process and other information like average time per image and minimum/maximum times.
It only works with GRire.v.0.0.3 or later because it needs General Maps to store the results.
Download link:
https://sourceforge.net/projects/grire/files/PluginPacks/TimersPack/
Evaluation of Image Browsing Interfaces for Smartphones and Tablets
Abstract
In this work we propose an early prototype of a video  browser for mobile devices with touchscreens. We concentrate on utilizing the thumbs because of the natural posture used with the devices when watching videos in landscape mode. The controls are only displayed when the user touches the screen and automatically rearrange themselves depending on the position of the thumbs. A combination of a radial menu and an extended seeker control with hierarchical browsing and bookmarking features enables the user to navigate quickly through videos.
browser for mobile devices with touchscreens. We concentrate on utilizing the thumbs because of the natural posture used with the devices when watching videos in landscape mode. The controls are only displayed when the user touches the screen and automatically rearrange themselves depending on the position of the thumbs. A combination of a radial menu and an extended seeker control with hierarchical browsing and bookmarking features enables the user to navigate quickly through videos.
2013 IEEE International Symposium on Multimedia